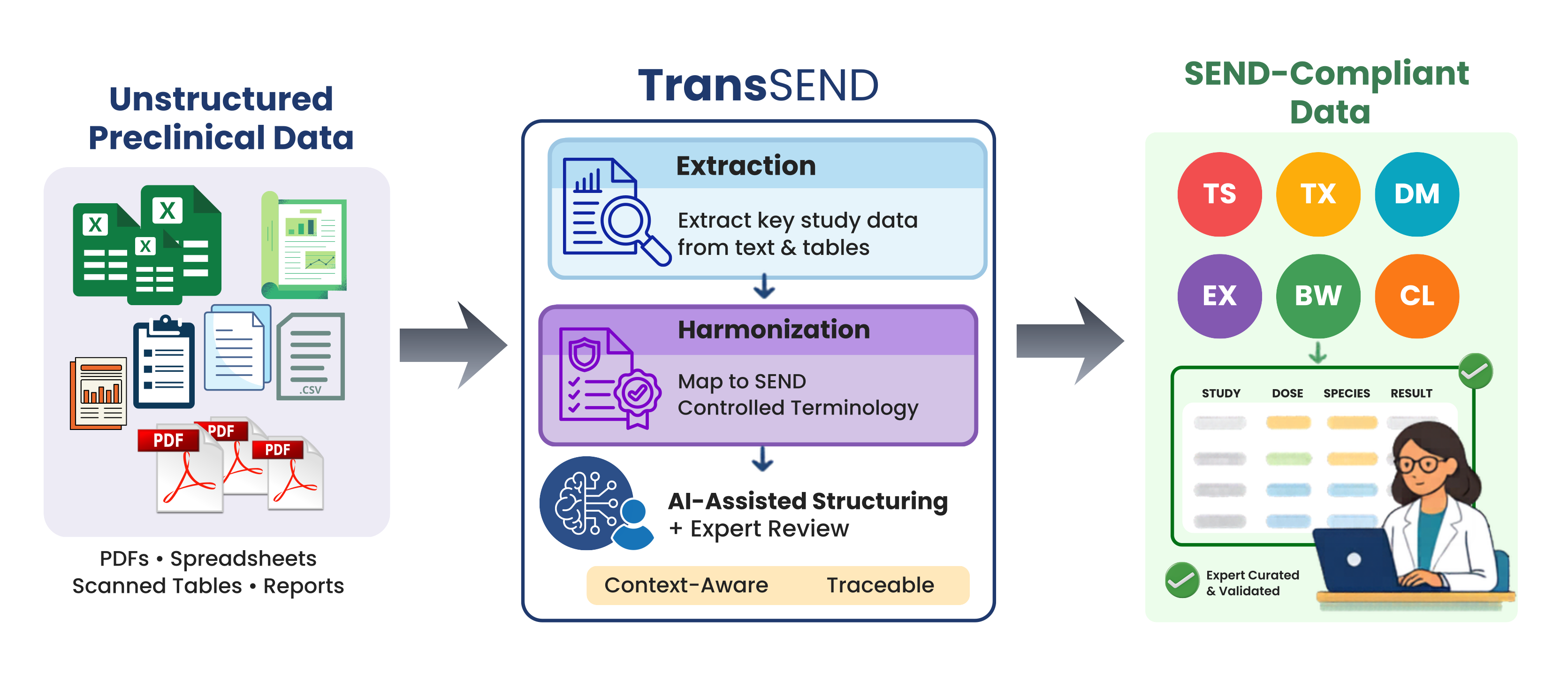
Preclinical toxicology studies generate an enormous amount of information: dense tables, semi-structured datasets, and long-form reports hidden away in PDFs. Turning that mix into consistent, reusable, and regulatory-ready data is often slow, expensive, and frustrating. SEND (Standard for Exchange of Nonclinical Data) was created to tackle exactly this problem. Developed by the Clinical Data Interchange Standards Consortium (CDISC) and adopted by regulators such as the FDA, SEND defines standardized, machine-readable structures (“domains”) for key study components—from trial design and dosing regimens to subject demographics and observations.
In principle, this makes it much easier to integrate, review, and compare data across studies and organizations. In reality, very little preclinical data is born in SEND format. Most of it needs to be extracted, interpreted, and transformed from heterogeneous sources, often by hand and with heavy reliance on expert curators. That is the gap TransSEND was built to close.
A Smarter Way to Structure Preclinical Data
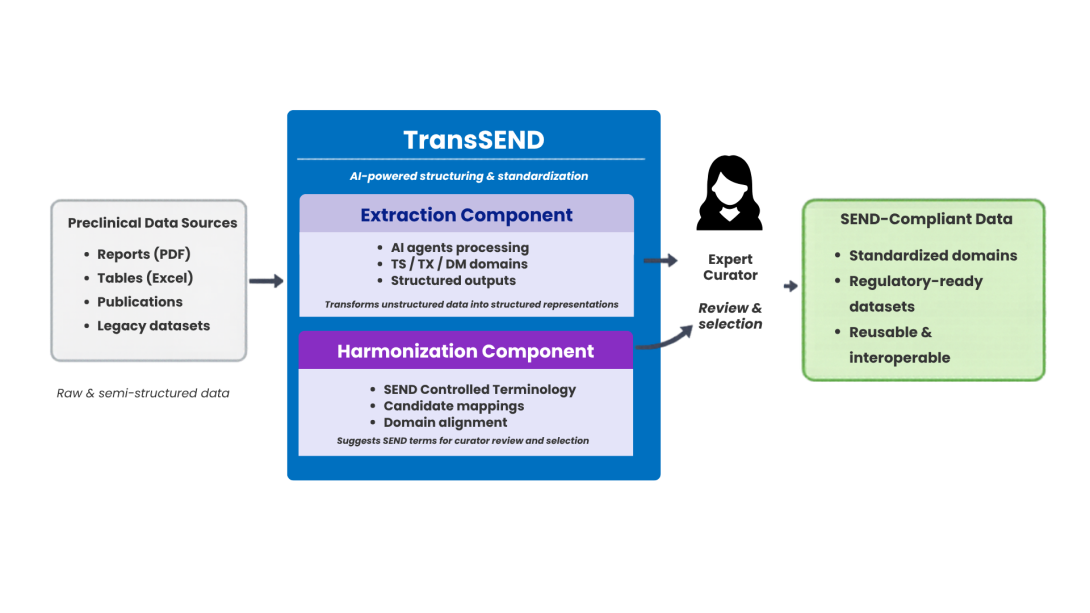
TransSEND, developed within the VICT3R project, sits between raw or semi-structured study outputs and SEND-compliant datasets. It takes fragmented preclinical information and turns it into structured, SEND-aligned outputs that are ready for expert review and downstream reuse. The goal is straightforward: make preclinical data interoperable, traceable, and reusable across studies and domains. Rather than trying to replace human curators, TransSEND is designed to amplify their expertise—so they can work faster and with greater consistency and confidence.
The tool achieves this through two core modular components:
- The Extraction Component: It processes unstructured or semi-structured study documents to identify and pull out relevant information—turning narrative text into structured data.
- The Harmonization Component: This aligns the extracted data with SEND Controlled Terminology. Instead of a “black box” making final decisions, it generates candidate mappings for expert curators to review and select, ensuring the final output follows strict domain conventions.
From Manual Work to Intelligent Automation
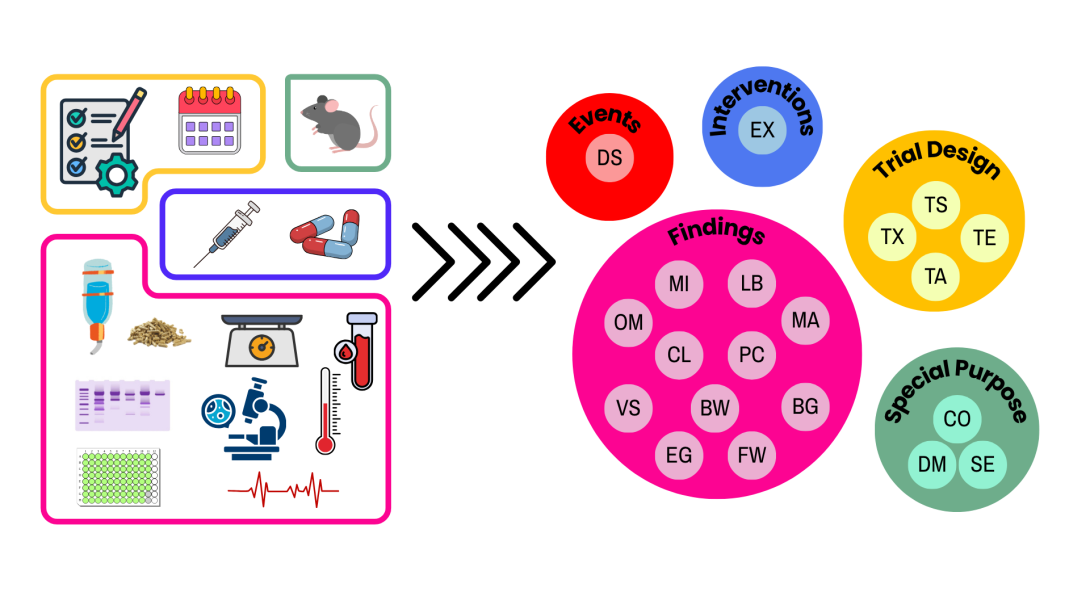
Traditional approaches to SEND curation rely on manual work or rigid rule-based systems that struggle with real-world variability. TransSEND takes a different route. It uses domain-aware AI to interpret, structure, and standardize complex scientific data, linking narrative text and tabular content into coherent SEND outputs. Key study elements are automatically organized into standard SEND domains, including:
- Trial Summary (TS): Core study attributes such as species, conditions, and overall design.
- Trial Set (TX): Experimental arms and treatment regimens.
- Demographics (DM): Subject-level data aligned with the study framework.
By structuring data in this way, TransSEND converts messy, varied reports into machine-readable representations while preserving scientific nuance.
Modular, Multi-Agent Intelligence
Under the hood, TransSEND uses a modular, multi-agent AI architecture. Each agent focuses on a specific SEND domain, and the agents collaborate to maintain cross-domain consistency. This design allows the system to:
- Parse and interpret complex scientific narratives.
- Infer implicit relationships in study design.
- Preserve semantic alignment across data layers.
Because it is adaptive rather than a static pipeline, the framework can accommodate the variability of real-world research data—from industrial preclinical studies to academic reports and legacy datasets.
Built for Real-World Complexity
Preclinical data appear in many formats: spreadsheets, narrative reports, scanned tables, or various combinations of these. TransSEND is designed to handle this heterogeneity without forcing users into a narrow workflow. It supports multiple study types, from neurobehavioral to developmental toxicity, and produces transparent, curation-ready outputs. Human experts remain firmly in control, reviewing and validating the structured results to ensure scientific accuracy.
Value That Scales with Your Data
By automating the most time-consuming steps of data structuring, TransSEND delivers several tangible benefits:
- Faster curation workflows.
- More consistent and reproducible datasets.
- Better interoperability for downstream AI and regulatory use.
- Scalable integration of legacy and literature-derived studies.
These capabilities help organizations unlock more value from their preclinical data—supporting advanced analytics, regulatory submissions, and emerging approaches such as Virtual Control Groups (VCGs).
A Vision for Smarter, Standards-Ready Science
Expert judgment will always be central to data curation. What is changing is how that expertise is applied. With TransSEND, specialists can spend less time cleaning and reformatting and more time validating insights and informing scientific decisions. TransSEND’s aim is simple: turn complexity into clarity and provide a faster, smarter, and more reliable foundation for modern preclinical research. If your organization is exploring how to modernize its data workflows or expand the impact of existing studies, we would be happy to show you what TransSEND can do.